阿里聯(lián)手中科院研發(fā)“聽音識(shí)人”技術(shù)提升AI安全防線 獲國(guó)際頂會(huì)認(rèn)可
幾年前,四川大學(xué)教師在某綜藝節(jié)目中展現(xiàn)了一個(gè)“挑戰(zhàn)不可能”的技能,女教師在不認(rèn)識(shí)辨別對(duì)象的情況下,蒙著眼與人交談幾句話,就能匹配聲音和人臉,準(zhǔn)確地從10多人中找到聲音的主人。
最近,中科院和阿里安全的研究者也挑戰(zhàn)了“不可能”,他們讓AI掌握了上述女教師的這項(xiàng)技能。通過訓(xùn)練AI模型,研究表情和聲音的關(guān)系。給定一段聲音和僅有一張正確人臉的若干張圖片,AI將為該聲音找到“主人”。經(jīng)驗(yàn)證,相較于人類67%的正確率,AI的準(zhǔn)確率接近90%。在“1對(duì)N”的匹配實(shí)驗(yàn)中,AI還能對(duì)聲音歸屬人臉的“可能性”進(jìn)行排序。
這種技術(shù)是一種自適應(yīng)的學(xué)習(xí)框架,用來挖掘和學(xué)習(xí)人臉與聲音的潛在聯(lián)系,該論文研究成果隨即也被CVPR 2021接收。
現(xiàn)有研究表明,人臉和聲音受到年齡、性別、生理結(jié)構(gòu)、語言習(xí)慣等共同因素的影響,兩者的聯(lián)系強(qiáng)烈而復(fù)雜多樣。該研究第一作者、中科院計(jì)算所博士研究生溫佩松介紹,中科院和阿里安全的研究團(tuán)隊(duì)將公開數(shù)據(jù)集中兩種類型的數(shù)據(jù)在共享空間中表示,從而達(dá)到跨模態(tài)匹配的目的,在學(xué)習(xí)策略上利用了數(shù)據(jù)集的局部和全局信息,提高了模型的學(xué)習(xí)效率和效果。
通俗來看,即聲音可能是音頻格式,人臉是圖片格式,兩類信息以不同的格式存儲(chǔ),難以比較,所以研究者將聲音和人臉“翻譯”成了同一種格式的信息,讓AI模型可以對(duì)兩種信息之間的關(guān)聯(lián)自行學(xué)習(xí)。AI學(xué)會(huì)了兩種信息的關(guān)聯(lián)性之后,就能幫聲音找到人臉,或者幫人臉找到聲音。因此,AI的這項(xiàng)技能不僅可以“聽音識(shí)人”,還能“見人知聲”。
溫佩松介紹,該研究進(jìn)行了三類實(shí)驗(yàn),第一種,給定一段聲音和僅含有一張正確人臉的若干張人臉圖片,AI匹配聲音和人臉的正確率最高可達(dá)87.2%;第二種,給定一段聲音和一張人臉,詢問AI這是否屬于同一個(gè)人,準(zhǔn)確率最高可達(dá)87.2%;第三種,給定一段聲音和含有若干張正確人臉的圖片,要求AI把所有人臉排序,使得正確的人臉盡可能靠前,AI也能準(zhǔn)確完成任務(wù)。該實(shí)驗(yàn)在公開測(cè)試集上一共測(cè)試了20076張人臉和21850段音頻,AI的表現(xiàn)都令人驚喜。
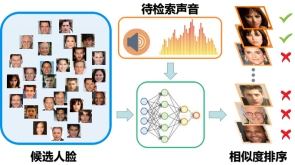
圖說:AI模型通過比較聲音和人臉圖片在共享空間的距離,推斷出相似度,按相似度將候選人臉排序。
在相同的任務(wù)上,如果待鑒別對(duì)象不限制性別,人類判斷的準(zhǔn)確率達(dá)81.3%,在限制性別的情況下,準(zhǔn)確率僅為57.1%,性別因素對(duì)AI的影響卻非常小,準(zhǔn)確率依然如上述結(jié)果,高于人類。
據(jù)阿里安全圖靈實(shí)驗(yàn)室資深算法專家華棠介紹,該技術(shù)后續(xù)將在內(nèi)容安全和賬戶安全領(lǐng)域探索應(yīng)用,對(duì)抗偽造類視頻攻擊,保護(hù)用戶財(cái)產(chǎn)和信息安全。“有些人利用偽造視頻試圖騙過認(rèn)證系統(tǒng),AI的這項(xiàng)技能將進(jìn)一步驗(yàn)證聲音與相應(yīng)真人是否匹配,防范欺詐,守護(hù)安全。”華棠說,這也是讓AI在提升安全水位上有更多用武之地。
- 免責(zé)聲明:本文內(nèi)容與數(shù)據(jù)僅供參考,不構(gòu)成投資建議。據(jù)此操作,風(fēng)險(xiǎn)自擔(dān)。
- 版權(quán)聲明:凡文章來源為“大眾證券報(bào)”的稿件,均為大眾證券報(bào)獨(dú)家版權(quán)所有,未經(jīng)許可不得轉(zhuǎn)載或鏡像;授權(quán)轉(zhuǎn)載必須注明來源為“大眾證券報(bào)”。
- 廣告/合作熱線:025-86256149
- 舉報(bào)/服務(wù)熱線:025-86256144
