Skywork UniPic開源了!從零預訓練打造圖片生成、理解和編輯一體化模型,生圖效果達SOTA
7月30日,昆侖萬維正式推出并開源采用自回歸路線的“多模態統一預訓練模型Skywork UniPic”,在單一模型中深度融合圖像理解、文本到圖像生成、圖像編輯三大核心能力。該模型基于大規模高質量數據進行端到端預訓練,具備良好的通用性與可遷移性。
秉持開放協作、共享創新的理念,昆侖萬維面向社區全面開放Skywork UniPic的核心資源。
01
Skywork UniPic:統一自回歸模型實現圖片生成、編輯與理解一體化
GPT-4o的迅速走紅,標志著人工智能領域多模態統一預訓練模型的成熟。Skywork UniPic延續了GPT-4o的自回歸范式,在單一模型中深度融合圖像理解、文本生成圖像(T2I)與圖像編輯三大核心任務,構建了真正統一的多模態模型架構。
傳統多模態統一模型多依賴VQ或VAE編碼器來壓縮視覺內容,雖然具備一定效果,但也存在局限性,它們更側重保留圖像的視覺細節而非語義信息,這會在一定程度上削弱模型的圖像理解能力。
為此,Skywork UniPic團隊借鑒Harmon架構設計,并在表征方式上做出關鍵調整:采用MAR編碼器作為圖像生成路徑的視覺表征基礎,同時引入SigLIP2作為圖像理解路徑的主干。
該結構設計的核心洞察在于:能否構建一個輕量級統一模型,在保持實際部署可行性的同時,在理解、生成與編輯任務上均達到頂尖性能?

Skywork-UniPic模型核心能力包含:
圖文理解:基于token預測完成文本的自回歸建模
圖像生成:采用掩碼自回歸方式,逐步生成圖像patch
圖像編輯:引入參考圖與編輯指令作為條件,生成編輯后的圖像
此外,Skywork-UniPic完成端到端優化流程,能夠實現生成、理解、編輯三大能力的協同訓練和相互促進,突破傳統方法中能力權衡的技術瓶頸。
這一架構設計不僅保持了自回歸模型的簡潔高效,更通過共享編碼器實現了跨任務的深度協同,為多模態統一模型的實用化部署奠定了堅實基礎。
用戶只需要輸入提示詞,Skywork-UniPic既可以像VLM一樣理解圖像、像T2I模型一樣生成圖片,還可以像美圖工具一樣,一鍵實現風格轉繪/吉卜力化的編輯功能。
02
模型優勢:1.5B輕量級規模性能逼近同類大參數統一模型,詮釋了“小而美”的技術美學
團隊在追求模型能力極限的同時,也堅持效率重要性的設計理念。Skywork UniPic以1.5B的緊湊參數規模,真正詮釋了“小而美”的技術美學:
多重技術亮點
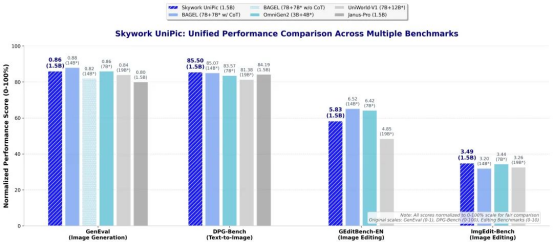
指令遵循能力媲美大型模型:在GenEval指令遵循評估中取得0.86的優異成績,超越了絕大多數同類統一模型,在無CoT的情況下取得了SOTA分數,逼近較大模型BAGEL(7B+7B*)帶CoT的0.88分;
復雜指令生圖能力領先:在DPG-Bench復雜指令生圖基準上達到85.5分的行業SOTA水平;
圖像編輯能力統一模型第一梯隊:GEditBench-EN獲得5.83分,ImgEdit-Bench達到3.49分,展現出精準的編輯執行能力;
參數效率優勢顯著:相比同類大參數統一模型(如BAGEL的14B總參數、UniWorld-V1的19B總參數),Skywork UniPic以1.5B的輕量級規模實現了接近甚至超越大參數模型的性能表現;
部署友好,真正可落地:模型在RTX 4090消費級顯卡上均可流暢運行,為廣大開發者和研究者提供了真正可落地的統一模型解決方案,大幅降低了技術應用門檻。
03
Skywork-UniPic是怎樣煉成的?
數據構建:億級高質量語料庫支撐統一模型預訓練
首先,Skywork UniPic的卓越性能,并非源自數據堆疊的蠻力,而是得益于一套高度精煉、系統優化的數據構建體系。
團隊突破了“更大即更強”的傳統認知邊界,通過約億級規模的精選預訓練語料與數百萬級任務精調(SFT)樣本,成功構建出一套面向理解、生成與編輯三大核心任務的高效能多模態訓練語料庫。
這一構建體系產生的語料庫不僅顯著壓縮了訓練資源成本,更在模型泛化能力與任務遷移表現上展現出驚人的性價比,充分驗證了小規模、精篩選、高質量數據對統一多模態模型訓練的可行性與潛力。
獎勵模型構建:數據質量驅動的智能評估體系
其次,為了確保Skywork UniPic在圖像生成和編輯任務上的卓越表現,我們設計了專用于圖像生成的Reward Model(Skywork-ImgReward)和專用于圖片編輯的Reward Model(Skywork-EditReward)。
其中,Skywork-ImgReward是基于強化學習訓練的Reward Model,相比于其他T2I Reward Model,Skywork-ImgReward在多個文生圖場景下的偏好選擇表現都更接近人類偏好。它不僅被用來作為文生圖數據質量的篩選,也可以在后續被用于圖像生成能力強化學習訓練中的獎勵信號,以及作為生成圖像的質量評估指標。
同時面對圖像編輯這一核心挑戰,我們創新性地構建了具有針對性的Skywork-EditReward,其被用作數據質量評估時可以自動剔除超過30%的低質量編輯樣本,在GEditBench-EN和ImgEdit-Bench基準測試中表現明顯改善。后續同樣也可以被用作圖像編輯強化學習訓練中的獎勵信號,以及作為圖像編輯的質量評估指標。
訓練體系優化與策略提升
MAR訓練優化體系:為提升模型表現,我們采用了兩項關鍵優化策略:首先,在數據層面引入覆蓋更廣視覺場景和類別的億級專有圖像數據,顯著拓展了模型的學習空間。其次,訓練過程中采用漸進式分辨率提升策略,先在256×256分辨率下建立穩定的底層特征抽取能力,再逐步遷移至512×512,以增強模型的語義理解和細粒度建模能力。
HARMON訓練優化體系:為進一步提升模型性能并兼顧訓練效率,我們設計了多階段分層分辨率訓練機制。在第一階段,模型在512×512分辨率下進行微調,聚焦基礎特征提取的穩定性與收斂性。隨后逐步提升輸入分辨率至1024×1024,促使模型更好地捕捉紋理、邊緣等高精度細節信息。
同時,我們采用分階段參數解凍策略,逐步釋放模型能力。在初始階段,僅訓練Projector模塊以實現視覺與語言特征的對齊,凍結主干網絡和LLM參數;接著在保持LLM編碼器凍結的前提下優化視覺主干;最后進入全量解凍階段,進行端到端聯合優化,實現多模態協同增強。
漸進式多任務訓練策略:為解決理解、生成和編輯三類任務難以兼得的問題,我們提出漸進式多任務訓練機制。
訓練初期,模型先專注于單一任務(如文本生成圖像),待其收斂后再引入理解與編輯任務,按照由易到難的順序逐步增加任務復雜度,避免多任務早期相互干擾。在精細化階段,我們通過獎勵模型篩選構建高質量訓練數據,采用動態閾值與多樣性采樣策略,確保樣本既具高置信度又具語義多樣性。
整體來看,以上策略在訓練過程中實現了結構合理的能力釋放和任務適應,顯著提升了模型在理解、生成和編輯等任務上的統一表現,達成真正意義上的“一專多能”。
過去半年,昆侖萬維已經開源了多個SOTA大模型,涵蓋獎勵模型、推理、軟件工程、多模態、空間智能等領域。今天,Skywork-UniPic正式加入“Skywork”開源大家庭,讓AI真正成為每個人觸手可及的創意伙伴。

龔斯軒
- 免責聲明:本文內容與數據僅供參考,不構成投資建議。據此操作,風險自擔。
- 版權聲明:凡文章來源為“大眾證券報”的稿件,均為大眾證券報獨家版權所有,未經許可不得轉載或鏡像;授權轉載必須注明來源為“大眾證券報”。
- 廣告/合作熱線:025-86256149
- 舉報/服務熱線:025-86256144
