僅32B,昆侖萬維開源“自主代碼智能體模型Skywork-SWE-32B”,拿下代碼開源SOTA
6月20日,昆侖萬維發(fā)布軟件工程(Software Engineering, SWE)自主代碼智能體基座模型Skywork-SWE,在開源32B模型規(guī)模下實現(xiàn)了業(yè)界最強的倉庫級代碼修復能力。昆侖萬維團隊通過構建超過1萬個可驗證的GitHub倉庫任務實例,打造出目前最大規(guī)模的可驗證GitHub倉庫級代碼修復的數(shù)據(jù)集,并系統(tǒng)性驗證了大模型在軟件工程任務上的數(shù)據(jù)縮放定律(Scaling Law)。
Skywork-SWE-32B模型在SWE-bench Verified基準上取得38.0% pass@1準確率,刷新Qwen2.5-Coder-32B系列模型在OpenHands代碼框架下的最佳成績。進一步引入測試時擴展技術后,模型表現(xiàn)提升至47.0%的準確率,不僅超越了現(xiàn)有參數(shù)規(guī)模在32B以下的開源模型,也顯著地縮小了與閉源模型之間的性能差距。

2025年被廣泛認為是智能體(Agent)模型的元年,其核心特征包括“超多輪交互”和“超長上下文處理”。在眾多應用方向中,軟件工程SWE任務正成為大語言模型智能體的關鍵應用場景之一。
相比傳統(tǒng)的代碼生成任務(如代碼編程題解答),SWE任務更加貼近真實的軟件開發(fā)流程,涵蓋了從定位BUG、修改源代碼,到驗證修復效果的完整閉環(huán)。這類任務通常源自GitHub倉庫中的實際代碼工程問題,具備高度的真實性、復雜性和挑戰(zhàn)性,是評估智能體模型能力的一個重要基準。
SWE任務的獨特之處在于,它對模型提出了更高要求:不僅需要支持多輪交互和長上下文推理,還需具備處理跨文件依賴、調用工具鏈,以及在復雜環(huán)境中持續(xù)修復代碼問題的能力。這些能力全面考驗了智能體模型的工程實踐水平與系統(tǒng)性思維能力。
三階段自動化流程,構建大規(guī)模、高質量SWE任務訓練數(shù)據(jù)集
盡管當前市面上已有不少工作聚焦于SWE任務并收集了相關的數(shù)據(jù)集,但當前的主流(訓練)數(shù)據(jù)集仍存在三大核心問題:
1. 缺乏可執(zhí)行環(huán)境與驗證機制:已有開源數(shù)據(jù)(如SWE-bench-extra、SWE-Fixer)通常缺乏環(huán)境或單元測試來驗證數(shù)據(jù)正確性,導致生成的修復難以驗證。
2. 高質量訓練數(shù)據(jù)稀缺:盡管某些數(shù)據(jù)集規(guī)模較大(如 SWE-Dev、SWE-Gym),但缺乏經(jīng)過嚴格驗證的訓練樣本,公開可用的高質量數(shù)據(jù)極為有限,導致開源模型在SWE任務上長期落后于閉源模型。
3. 數(shù)據(jù)規(guī)模法則適用性不明確:相較于自然語言領域中的任務,SWE任務現(xiàn)有的公開訓練數(shù)據(jù)體量較小,尚無法有效驗證數(shù)據(jù)擴展是否能帶來模型能力的持續(xù)增長。
為打破上述瓶頸,并且打造出具備工程實用性的SWE代碼智能體模型,昆侖萬維團隊首先在訓練階段自行構建了一套自動化、結構化、可復現(xiàn)的SWE數(shù)據(jù)收集與驗證流程,共分為三個階段、九個步驟(如下圖所示)。最終團隊構建出超1萬條高質量任務實例、8千條多輪交互的軌跡,為模型訓練提供堅實基礎。

圖丨Skywork-SWE完整數(shù)據(jù)收集與驗證流程
Skywork-SWE作為萬級高質量可驗證數(shù)據(jù)集,驅動智能體模型能力躍遷
在上述三個階段過程中,團隊實施了嚴格的數(shù)據(jù)篩選與構建流程。如下圖所示,團隊從最初超過15萬條候選代碼倉庫元數(shù)據(jù)中,最終篩選出約1萬條高質量實例,構建出當前規(guī)模最大、質量最高的可驗證SWE任務(訓練)數(shù)據(jù)集——Skywork-SWE。

圖丨數(shù)據(jù)構建過程中各個階段數(shù)據(jù)樣本量變化示意
Skywork-SWE數(shù)據(jù)集在任務數(shù)量與代碼覆蓋廣度方面,遠超現(xiàn)有同類數(shù)據(jù)集(如SWE-Gym Lite與SWE-bench Verified),為大模型提供了豐富、多樣且貼近實際的軟件工程任務樣本,持續(xù)推動智能體模型的能力進化。此外,Skywork-SWE數(shù)據(jù)集不僅涵蓋如Pydantic、SQLGlot、DVC等主流開源項目,還包含大量中小型倉庫,呈現(xiàn)出高度貼近真實開發(fā)生態(tài)的任務分布特征。這種貼近真實開發(fā)生態(tài)的數(shù)據(jù)構成,有助于提升模型在復雜多樣場景下的問題解決能力。

圖丨Skywork-SWE數(shù)據(jù)集的GitHub倉庫詞云
Skywork-SWE登頂32B開源SOTA
“Less artifact, more intelligence”(更少的人工約束,更多智能發(fā)揮) 是團隊開發(fā)軟件工程自主代碼智能體模型的核心理念。我們主張賦予AI更大自主權,由其決定工具使用與任務執(zhí)行方式,而非人為預先設定規(guī)則流程。基于這一理念,最終選用目前最具自主性的開源OpenHands框架。
基于Skywork-SWE數(shù)據(jù)集的高質量智能體軌跡,昆侖萬維團隊微調得到Skywork-SWE-32B模型,該模型在SWE-bench Verified測評中取得優(yōu)異成績。截至目前,Skywork-SWE-32B在SWE-Bench榜單中成為當前性能最強的32B開源代碼智能體大模型,刷新SWE-bench Verified基準上同等規(guī)模模型的最佳成績,充分展示了其工程實用價值:
1.Skywork-SWE-32B測評結果超越相同參數(shù)規(guī)模的模型。Skywork-SWE-32B基于開源OpenHands代碼Agent框架,實現(xiàn)了38.0% pass@1的準確率,達到了Qwen2.5-Coder-32B系列模型在OpenHands代碼框架下的最優(yōu)水平。更為關鍵的是,實驗結果進一步表明:隨著訓練數(shù)據(jù)規(guī)模的持續(xù)擴展,模型性能持續(xù)提升,充分驗證了“數(shù)據(jù)規(guī)模擴展帶來的性能增益”在軟件工程任務中的有效性與適用性。
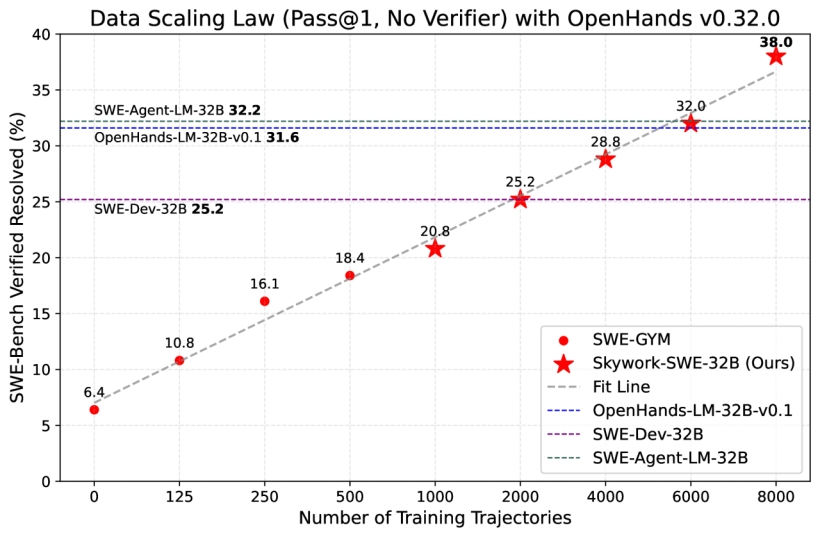
2.應用測試時擴展技術之后,Skywork-SWE-32B取得了最優(yōu)性能。在引入測試時擴展技術(Test-Time Scaling,TTS)后,Skywork-SWE-32B (+ TTS) 的pass@1準確率進一步提升至47.0%,刷新了32B參數(shù)規(guī)模以下開源模型的SOTA。更值得關注的是,Skywork-SWE-32B在與參數(shù)量高達671B的DeepSeek-V3-0324模型對比中仍展現(xiàn)出明顯優(yōu)勢,領先8.2個百分點。
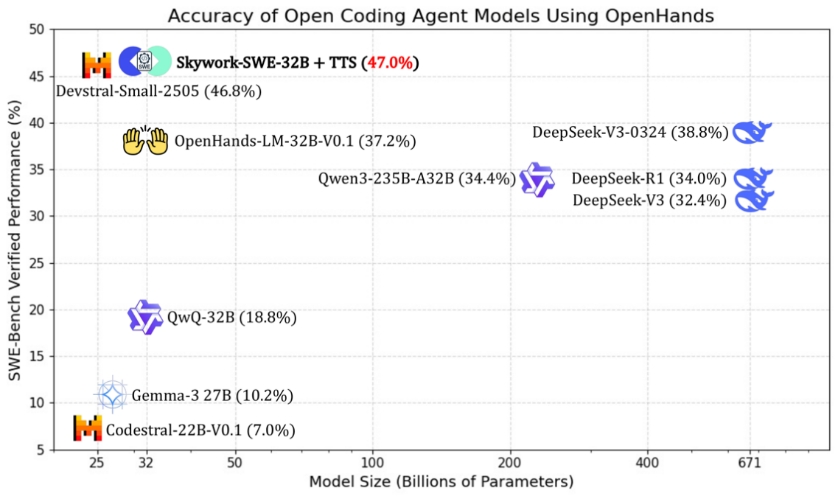
3.Skywork-SWE-32B (+ TTS) 的表現(xiàn)接近甚至超越多數(shù)主流閉源大模型。Skywork-SWE-32B (+ TTS) 的pass@1準確率顯著超越了GPT-4.1-mini(23.86%)、 Claude 3.5 HaiKu(40.6%)和 OpenAI-o1-preview (41.3%),并且領先于Claude v3.5(46.0%)。

持續(xù)探索更多Agent任務場景
過去半年多時間,昆侖萬維在獎勵模型、多模態(tài)、推理、視頻生成等方向開源了一系列SOTA級別模型,如今又在Agent(SWE任務)方向再下一城。繼5月天工超級智能體(Skywork Super Agents)面向全球發(fā)布后,今天我們又發(fā)布并開源了自主代碼智能體模型Skywork-SWE-32B模型,這不僅是公司堅定開源策略的重要實踐,更代表了我們對Agent在辦公任務、SWE任務場景中的重要探索。
通過Skywork-SWE數(shù)據(jù)集的構建,以及自主代碼智能體模型Skywork-SWE-32B模型的發(fā)布,團隊研究表明高質量且可執(zhí)行驗證的數(shù)據(jù)是提升代碼智能體模型性能的關鍵瓶頸,系統(tǒng)化的數(shù)據(jù)擴展策略將在推動開源模型性能突破中發(fā)揮關鍵作用。基于此,我們期望Skywork-SWE-32B的開源,能夠助力社區(qū)在大語言模型驅動的軟件工程研究中持續(xù)演進。
未來,Skywork-SWE-32B模型將進一步拓展多編程語言支持以覆蓋更廣泛的開發(fā)場景,并探索融合運行時測試反饋的強化學習機制,為構建真正具備智能軟件開發(fā)能力的大語言模型奠定堅實基礎。同時,昆侖萬維也將積極探索更多Agent任務場景。
龔斯軒
- 免責聲明:本文內容與數(shù)據(jù)僅供參考,不構成投資建議。據(jù)此操作,風險自擔。
- 版權聲明:凡文章來源為“大眾證券報”的稿件,均為大眾證券報獨家版權所有,未經(jīng)許可不得轉載或鏡像;授權轉載必須注明來源為“大眾證券報”。
- 廣告/合作熱線:025-86256149
- 舉報/服務熱線:025-86256144
